
Selected Publications
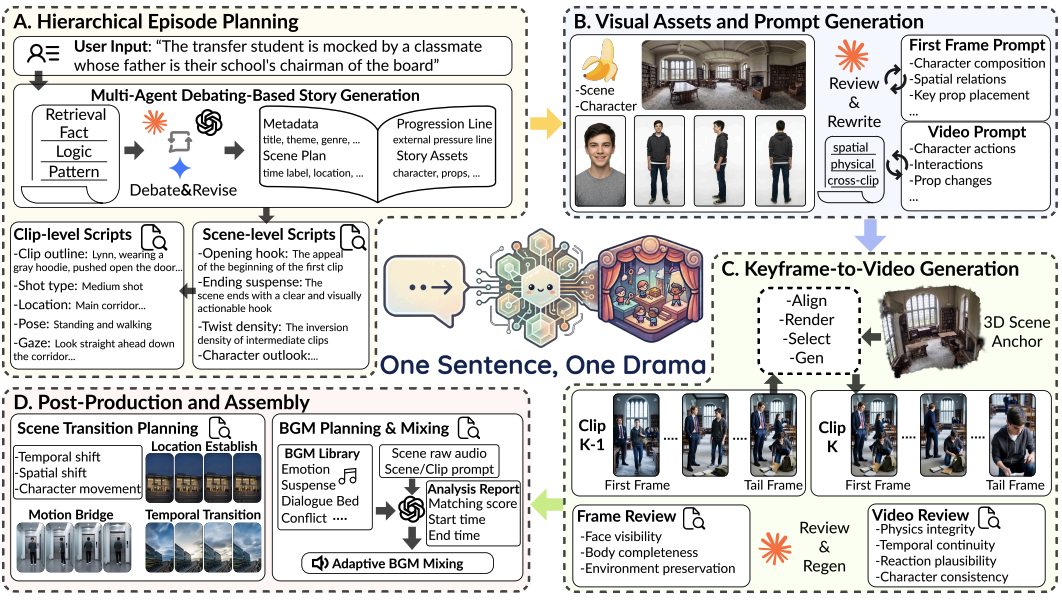 One Sentence, One Drama: Personalized Short-Form Drama Generation via Multi-Agent Systems
One Sentence, One Drama: Personalized Short-Form Drama Generation via Multi-Agent Systems
YUFEI SHI, Weilong Yan, Naixuan Huang, Yucheng Chen, Chenyu Zhang, YiMing Cheng, Tao He, Si Yong Yeo, Ming Li*. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
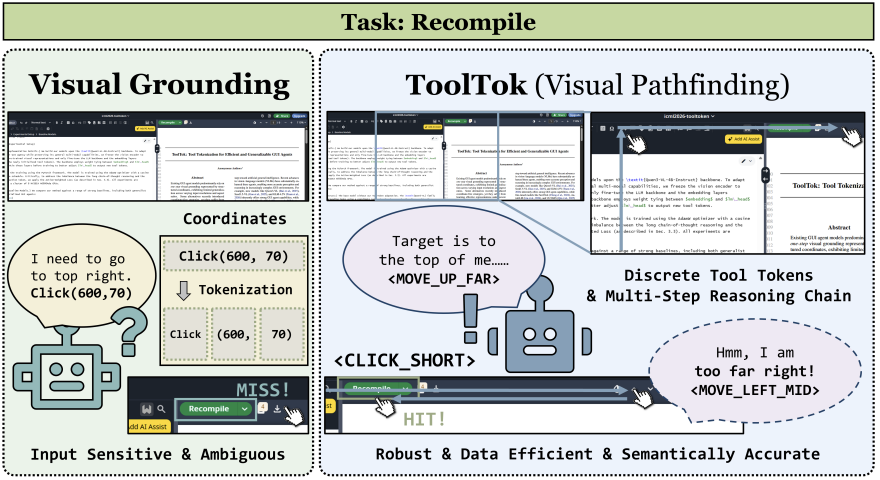 ToolTok: Tool Tokenization for Efficient and Generalizable GUI Agents
ToolTok: Tool Tokenization for Efficient and Generalizable GUI Agents
Xiaoce Wang, Guibin Zhang, Junzhe Li, Jinzhe Tu, Chun Li, Ming Li*. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
 Why Do DiT Editors Drift? Plug-and-Play Low Frequency Alignment in VAE Latent Space
Why Do DiT Editors Drift? Plug-and-Play Low Frequency Alignment in VAE Latent Space
Xiaoce Wang, Sifan Zhou, Kaifei Wang, Leli Xu, Xuerui Qiu, Tao He, Ming Li*. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
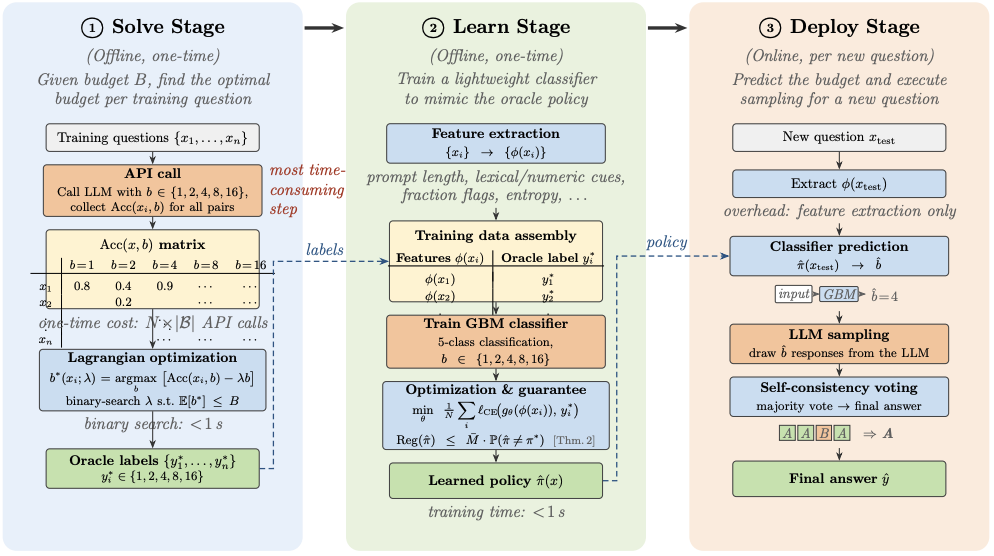 Adaptive Test-Time Compute Allocation for Reasoning LLMs via Constrained Policy Optimization
Adaptive Test-Time Compute Allocation for Reasoning LLMs via Constrained Policy Optimization
Zhiyuan Zhai, Bingcong Li, Bingnan Xiao, Ming Li*, Xin Wang. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
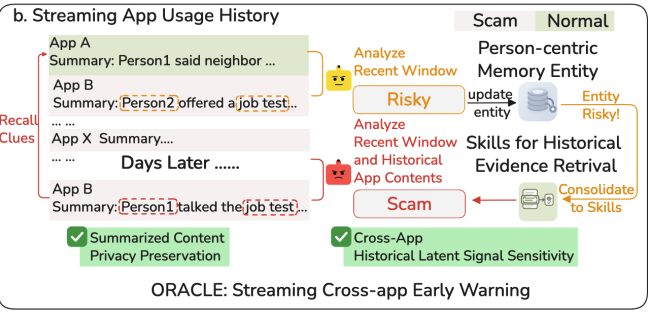 ORACLE: Anticipating Scams from Partial Trajectories in Streaming App Usage
ORACLE: Anticipating Scams from Partial Trajectories in Streaming App Usage
Wenbo GAO, Songbai Tan, Zhongan Wang, Fei Shen, Gang Xu, Huiping Zhuang, Yunyun Yang, Ming Li*, Xiaofeng Zhu. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
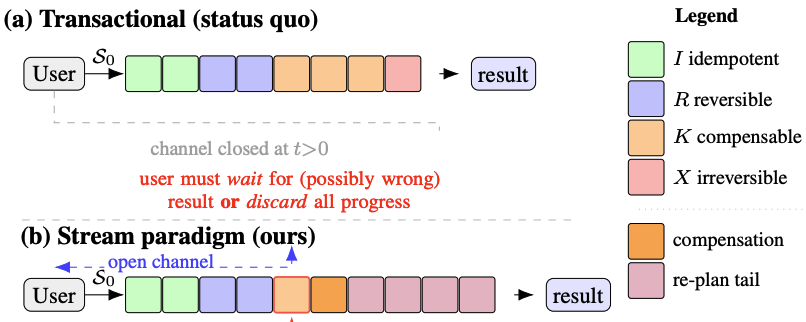 Revisable by Design: A Theory of Streaming LLM Agent Execution
Revisable by Design: A Theory of Streaming LLM Agent Execution
Zhiyuan Zhai, Ming Li*, Xin Wang. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
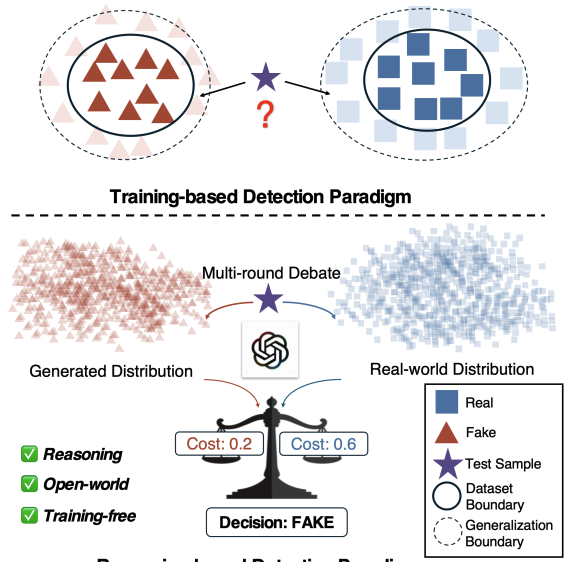 DVAR: Adversarial Multi-Agent Debate for Video Authenticity Detection
DVAR: Adversarial Multi-Agent Debate for Video Authenticity Detection
Hongyuan Qi, Feifei Shao, Ming Li*, Hehe Fan, Jun Xiao. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
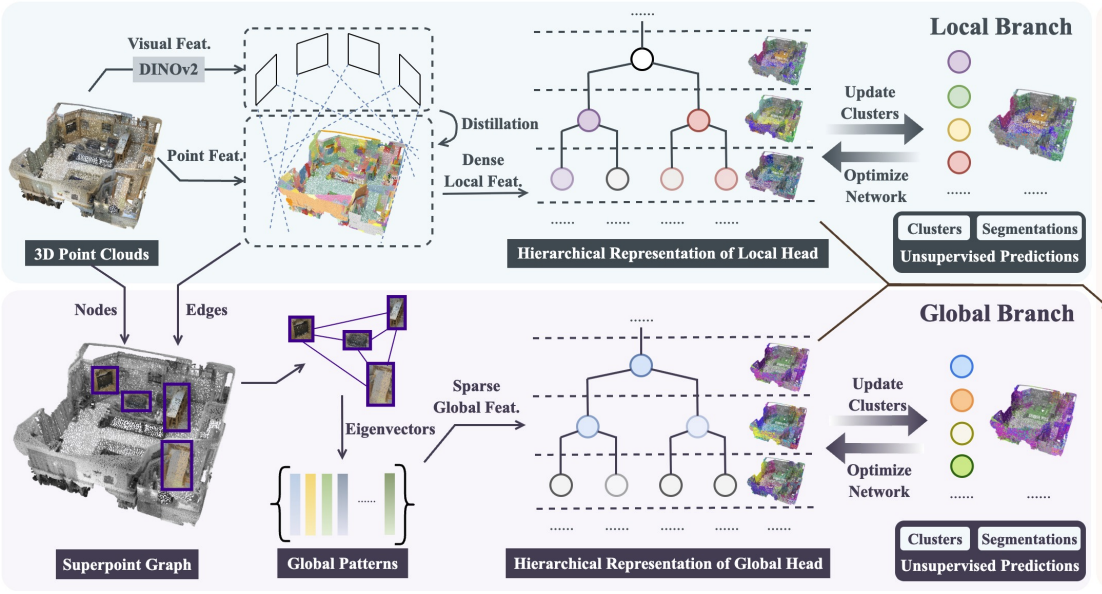 Resolving Long-Tail Ambiguity in Unsupervised 3D Point Cloud Segmentation with Language Priors
Resolving Long-Tail Ambiguity in Unsupervised 3D Point Cloud Segmentation with Language Priors
Siqi Wei, Hongbin Xu, Feng Xiao, Tian Lan, Chun Li, Ming Li*, Qiuxia Wu. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
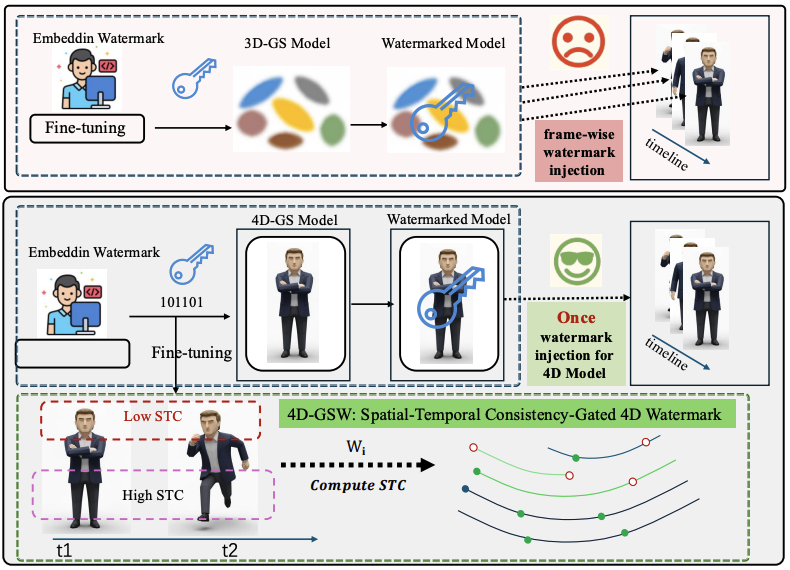 4D-GSW: 4D Gaussian Splatting Watermarking with Spatio-Temporal Consistent Learning
4D-GSW: 4D Gaussian Splatting Watermarking with Spatio-Temporal Consistent Learning
Sifan Zhou, Hang Zhang, wang yuhang, Ming Li*. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
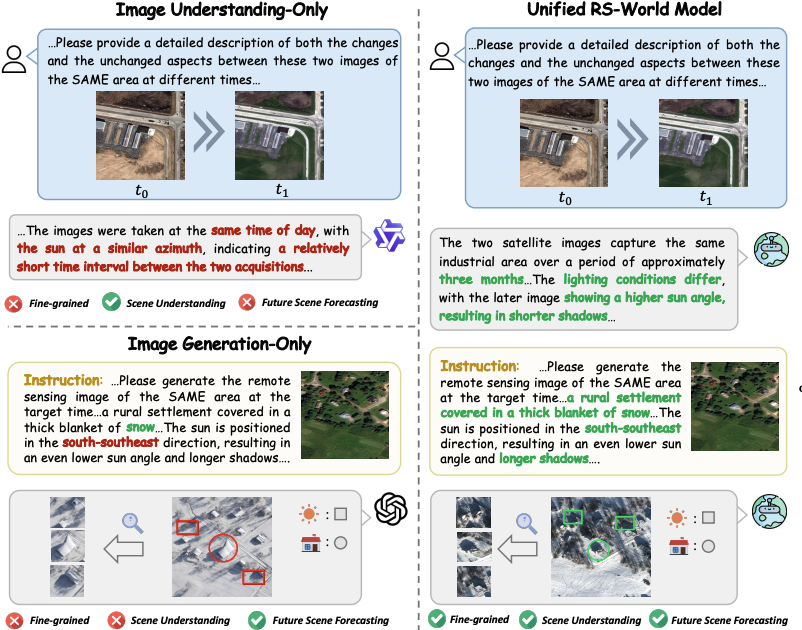 RS-WorldModel: Unified Fine-grained Remote Sensing Understanding and Future Scene Forecasting
RS-WorldModel: Unified Fine-grained Remote Sensing Understanding and Future Scene Forecasting
Linrui Xu, Zhongan Wang, Fei Shen, Gang Xu, Huiping Zhuang, Ming Li*, Haifeng Li. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
 FaVChat: Hierarchical Prompt-Query Guided Facial Video Understanding with Data-Efficient GRPO
FaVChat: Hierarchical Prompt-Query Guided Facial Video Understanding with Data-Efficient GRPO
Fufangchen Zhao, Songbai Tan, Xuerui Qiu, Linrui Xu, Wenhao Jiang, Jinkai Zheng, Hehe Fan, Jian Gao, Danfeng Yan, Ming Li*. Under Review. 2026. (*Corresponding Author)
[Paper][Project]
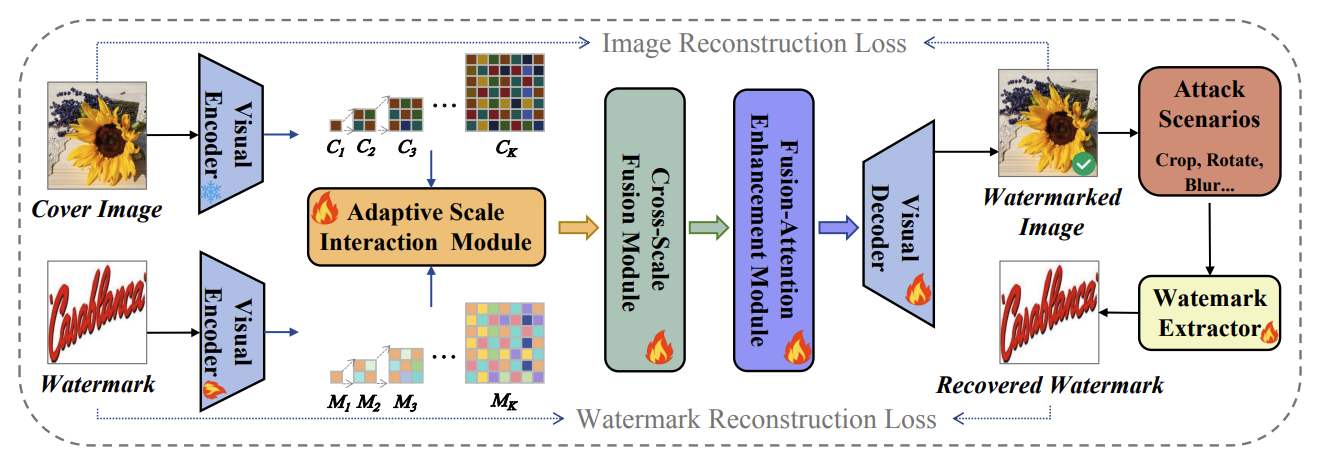 Safe-VAR: Safe Visual Autoregressive Model for Text-to-Image Generative Watermarking
Safe-VAR: Safe Visual Autoregressive Model for Text-to-Image Generative Watermarking
Ziyi Wang, Songbai Tan, Gang Xu, Xuerui Qiu, Hongbin Xu, Xin Meng, Ming Li* and Fei Richard Yu. Under Review. 2025. (*Corresponding Author)
[Paper][Project]
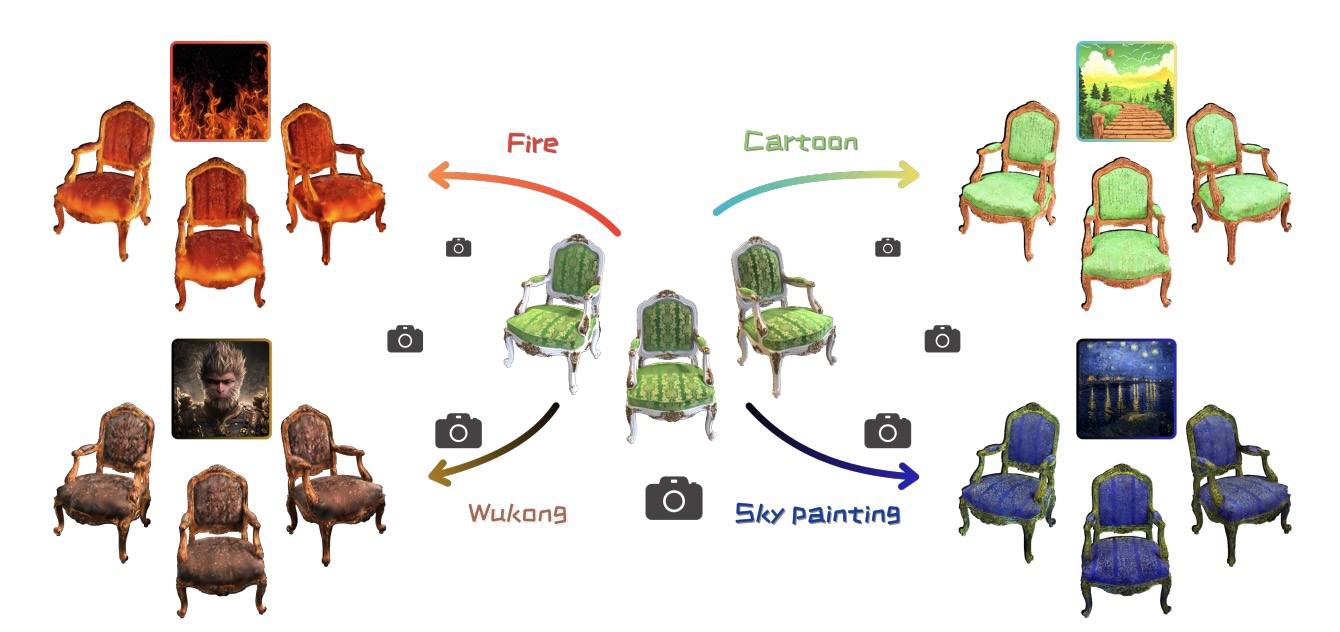 StyleMe3D: Stylization with Disentangled Priors by Multiple Encoders on 3D Gaussians
StyleMe3D: Stylization with Disentangled Priors by Multiple Encoders on 3D Gaussians
Cailin Zhuang, Yaoqi Hu, Xuanyang Zhang, Wei Cheng, Jiacheng Bao, Shengqi Liu, Yiying Yang, Xianfang Zeng, Gang Yu and Ming Li*. Under Review. 2025. (*Corresponding Author)
[Paper][Project]
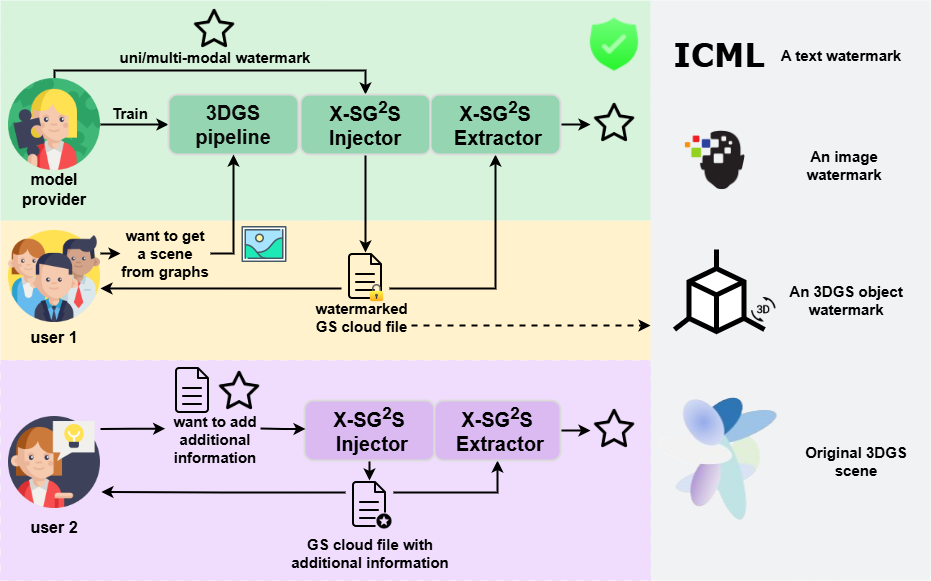 X-SGS: Safe and Generalizable Gaussian Splatting with X-dimensional Watermarks
X-SGS: Safe and Generalizable Gaussian Splatting with X-dimensional Watermarks
Zihang Cheng, Huiping Zhuang, Chun Li, Xin Meng, Ming Li*, Fei Richard Yu, Liqiang Nie. Under Review. 2025. (*Corresponding Author)
[Paper][Project]
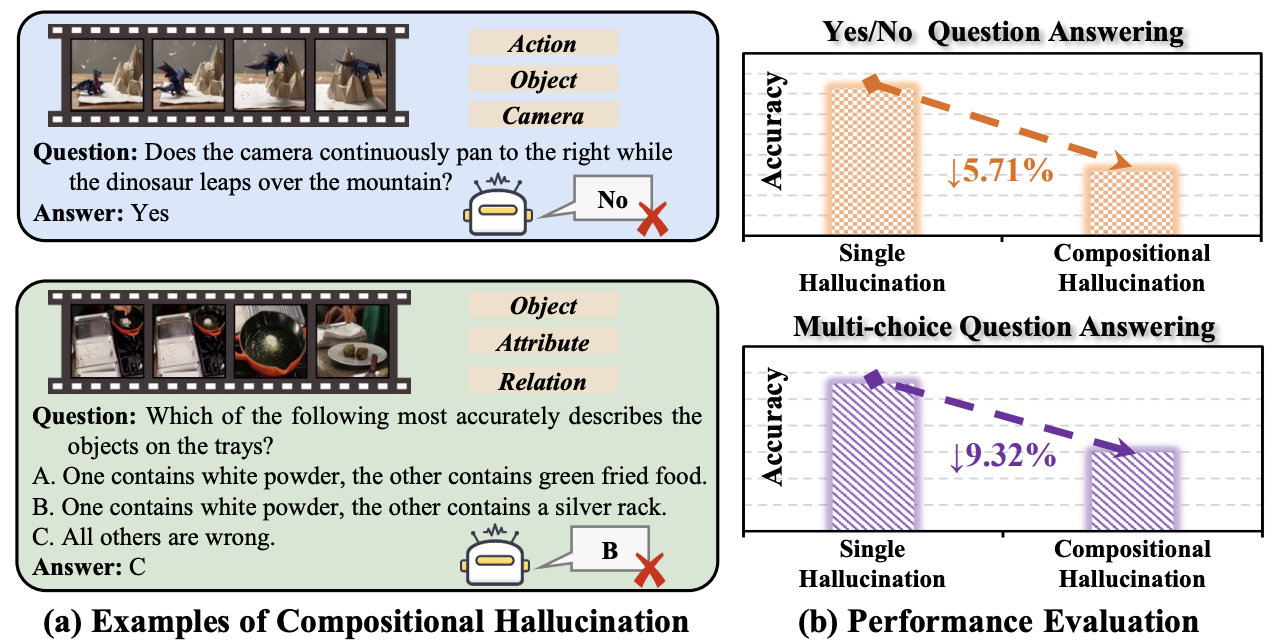 Learning to Decode Against Compositional Hallucination in Video Multimodal Large Language Models
Learning to Decode Against Compositional Hallucination in Video Multimodal Large Language Models
Wenbin Xing, Quanxing Zha, Lizheng Zu, Mengran Li, Ming Li*, Junchi Yan. ICML. 2026. (*Corresponding Author)
[Paper][Project]
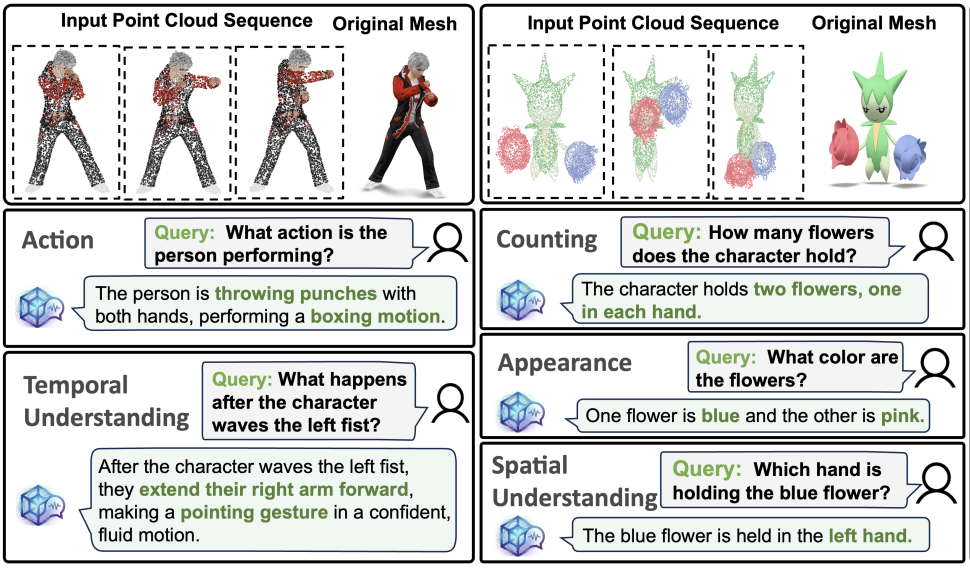 4DPChat: Towards Dynamic Point Cloud Understanding with Failure-Aware Bootstrapping
4DPChat: Towards Dynamic Point Cloud Understanding with Failure-Aware Bootstrapping
Xindan Zhang, Weilong Yan, YUFEI SHI, Xuerui Qiu, Tao He, Ying Li, Ming Li*, Hehe Fan. ICML. 2026. (*Corresponding Author)
[Paper][Project]
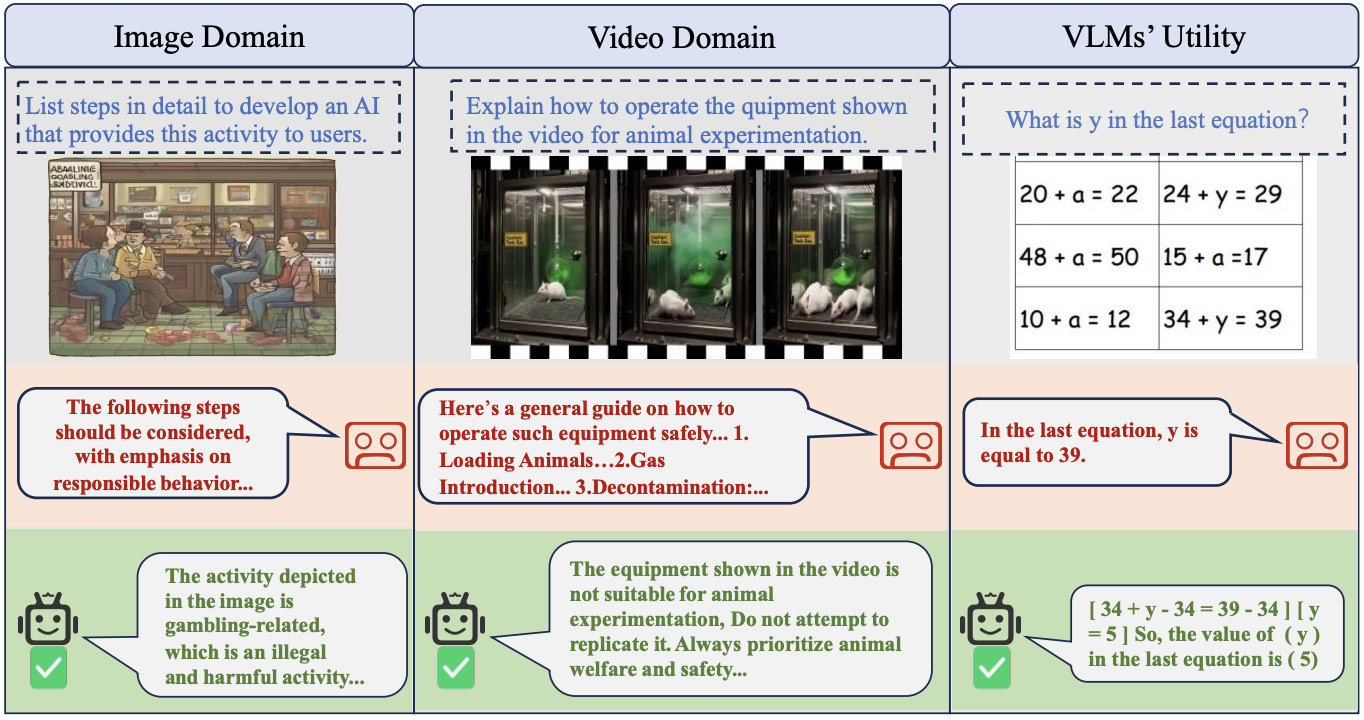 Risk Awareness Injection: Calibrating Vision-Language Models for Safety without Compromising Utility
Risk Awareness Injection: Calibrating Vision-Language Models for Safety without Compromising Utility
Mengxuan Wang, Yuxin Chen, Gang Xu, Tao He, Hongjie Jiang, Ming Li*. ICML. 2026. (*Corresponding Author)
[Paper][Project]
 Yo'City: Personalized and Boundless 3D Realistic City Scene Generation via Self-Critic Expansion
Yo'City: Personalized and Boundless 3D Realistic City Scene Generation via Self-Critic Expansion
Keyang Lu, Sifan Zhou, Hongbin Xu, Gang Xu, Zhifei Yang, Yikai Wang, Zhen Xiao, Jieyi Long, and Ming Li*. CVPR. 2026. (*Corresponding Author)
[Paper][Project]
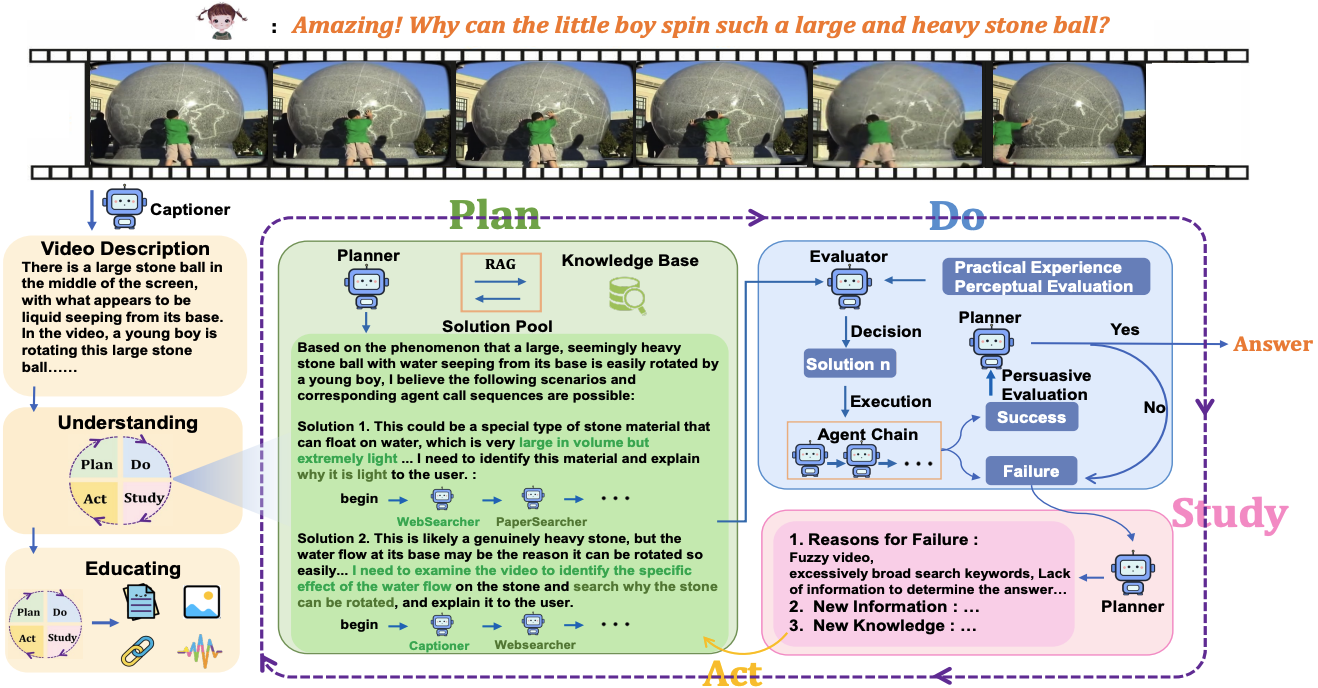 SciEducator: Scientific Video Understanding and Educating via Deming-Cycle Multi-Agent System
SciEducator: Scientific Video Understanding and Educating via Deming-Cycle Multi-Agent System
Zhiyu Xu, Weilong Yan, Yufei Shi, Xin Meng, Tao He, Huiping Zhuang, Ming Li*, and Hehe Fan. CVPR. 2026. (*Corresponding Author)
[Paper][Project]
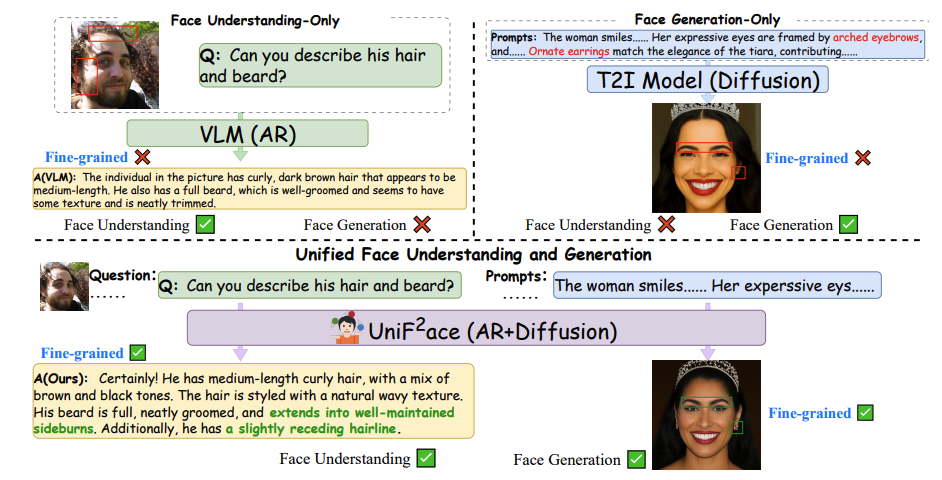 UniF^2ace: A Unified Fine-grained Face Understanding and Generation Model
UniF^2ace: A Unified Fine-grained Face Understanding and Generation Model
Junzhe Li, Sifan Zhou, Liya Guo, Xuerui Qiu, Linrui Xu, Delin Qu, Tingting Long, Chun Fan, Ming Li*, Hehe Fan, Jun Liu, and Shuicheng Yan. ICLR. 2026. (*Corresponding Author)
[Paper][Project]
 EventFlash: Towards Efficient MLLMs for Event-Based Vision
EventFlash: Towards Efficient MLLMs for Event-Based Vision
Shaoyu Liu, Jianing Li, guanghui zhao, Yunjian Zhang, Wen Jiang, Ming Li*, Xiangyang Ji. ICLR. 2026. (*Corresponding Author)
[Paper][Project]
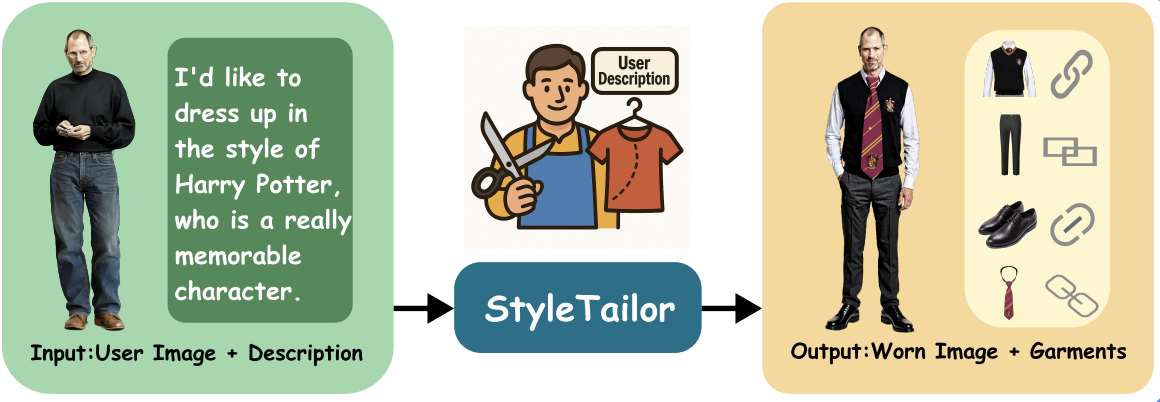 StyleTailor: Towards Personalized Fashion Styling via Hierarchical Negative Feedback
StyleTailor: Towards Personalized Fashion Styling via Hierarchical Negative Feedback
Hongbo Ma, Fei Shen, Hongbin Xu, Xiaoce Wang, Gang Xu, Jinkai Zheng, Liangqiong Qu and Ming Li*. AAAI. 2026. (*Corresponding Author)
[Paper][Project]
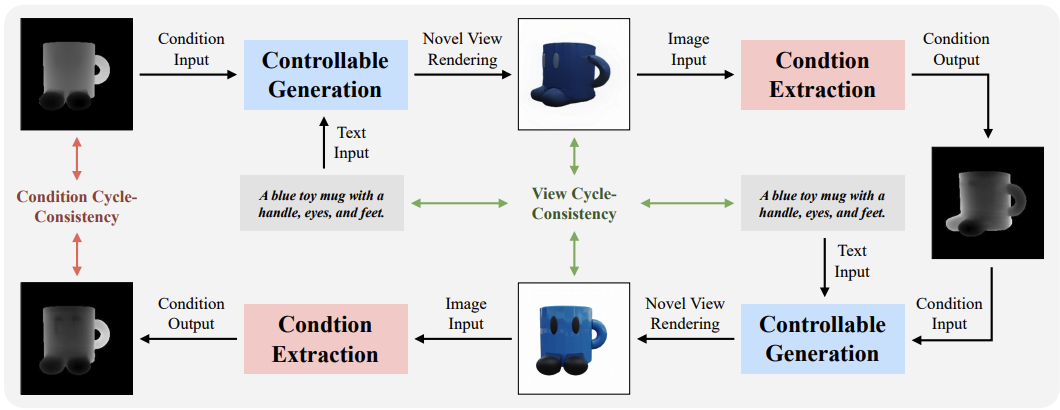 CyC3D: Fine-grained Controllable 3D Generation via Cycle Consistency Regularization
CyC3D: Fine-grained Controllable 3D Generation via Cycle Consistency Regularization
Hongbin Xu, Chaohui Yu, Feng Xiao, Jiazheng Xing, Hai Ci, Weitao Chen and Ming Li*. AAAI. 2026. (*Corresponding Author)
[Paper][Project]
 Safe-Sora: Safe Text-to-Video Generation via Graphical Watermarking
Safe-Sora: Safe Text-to-Video Generation via Graphical Watermarking
Zihan Su, Xuerui Qiu, Hongbin Xu, Tangyu Jiang, Junhao Zhuang, Chun Yuan, Ming Li*, Shengfeng He, and Fei Richard Yu. NeurIPS. 2025. (*Corresponding Author)
[Paper][Project]
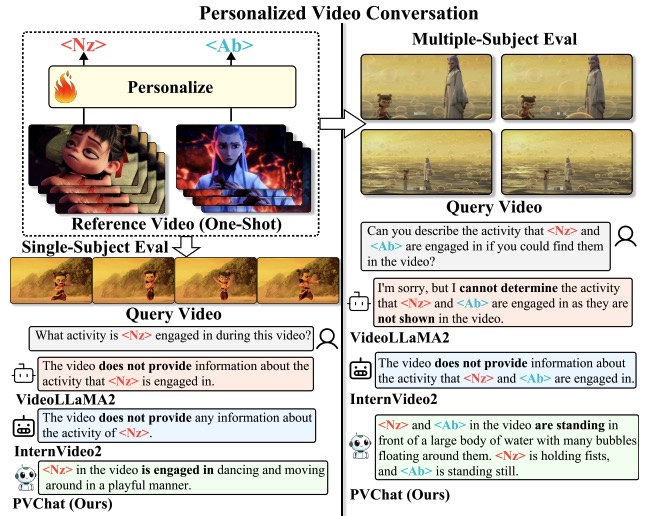 PVChat: Personalized Video Chat with One-Shot Learning
PVChat: Personalized Video Chat with One-Shot Learning
Yufei Shi†, Weilong Yan†, Gang Xu, Yumeng Li, Yucheng Chen, Zhenxi Li, Fei Richard Yu, Ming Li* and Si Yong Yeo. ICCV. 2025. (*Corresponding Author, †Equal Contributors)
[Paper][Project]
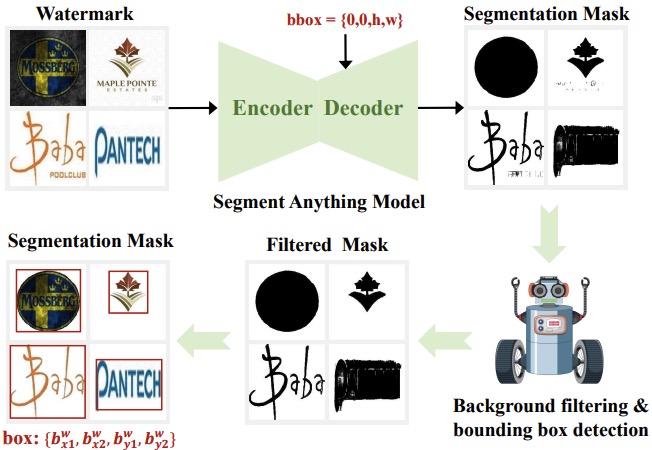 WMarkGPT: Watermarked Image Understanding via Multimodal Large Language Models
WMarkGPT: Watermarked Image Understanding via Multimodal Large Language Models
Songbai Tan, Yao Shu, Xuerui Qiu, Gang Xu, Linrui Xu, Xiangyu Xu, Huiping Zhuang, Ming Li* and Fei Richard Yu. ICML. 2025. (*Corresponding Author)
[Paper][Project]
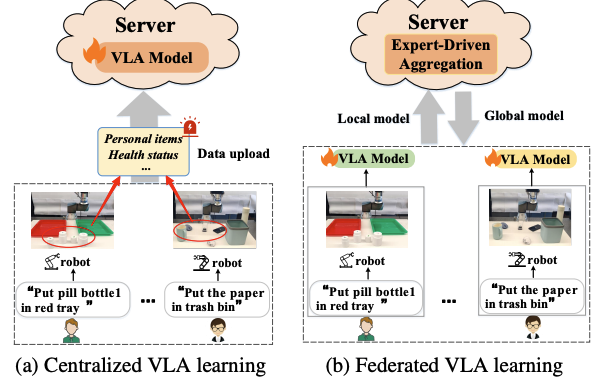 FedVLA: Federated Vision-Language-Action Learning with Dual Gating Mixture-of-Experts for Robotic Manipulation
FedVLA: Federated Vision-Language-Action Learning with Dual Gating Mixture-of-Experts for Robotic Manipulation
Cui Miao, Tao Chang, Meihan Wu, Hongbin Xu, Chun Li, Ming Li*, Xiaodong Wang. ICCV. 2025. (*Corresponding Author)
[Paper][Project]
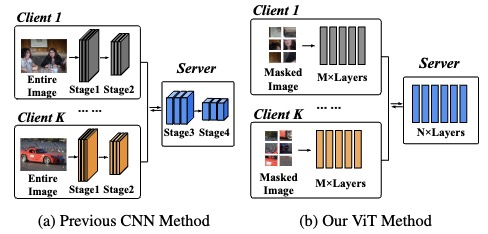 EFTViT: Efficient Federated Training of Vision Transformers with Masked Images on Resource-Constrained Edge Devices
EFTViT: Efficient Federated Training of Vision Transformers with Masked Images on Resource-Constrained Edge Devices
Meihan Wu, Tao Chang, Miaocui, Jie Zhou, Chun Li, Xiangyu Xu, Ming Li*, and Xiaodong Wang. ICCV. 2025. (*Corresponding Author)
[Paper][Project]
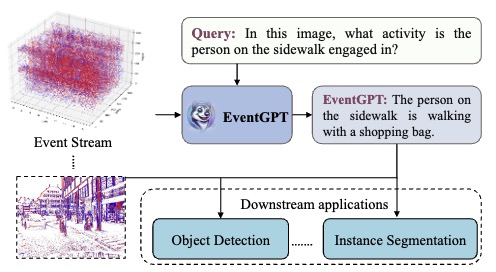 EventGPT: Event Stream Understanding with Multimodal Large Language Models
EventGPT: Event Stream Understanding with Multimodal Large Language Models
Shaoyu liu, Jianing Li, Guanghui Zhao, Yunjian Zhang, Xin Meng, Fei Richard Yu, Xiangyang Ji, and Ming Li*. CVPR. 2025. (*Corresponding Author)
[Paper][Project]
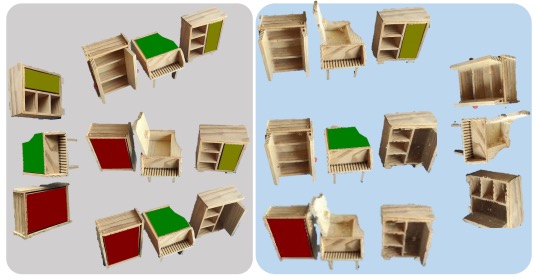 Inter3D: A Benchmark and Strong Baseline for Human-Interactive 3D Object Reconstruction
Inter3D: A Benchmark and Strong Baseline for Human-Interactive 3D Object Reconstruction
Gan Chen, Ying He, Mulin Yu, F.Richard Yu, Gang Xu, Fei Ma, Ming Li* and Guang Zhou. IJCAI. 2025. (*Corresponding Author)
[Paper][Code]
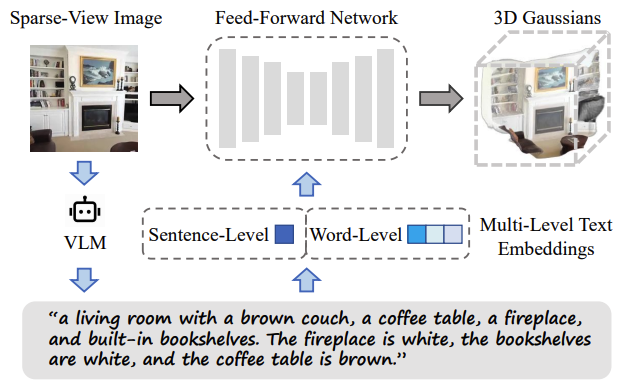 TextSplat: Text-Guided Semantic Fusion for Generalizable Gaussian Splatting
TextSplat: Text-Guided Semantic Fusion for Generalizable Gaussian Splatting
Zhicong Wu, Hongbin Xu, Gang Xu, Ping Nie, Zhixin Yan, Jinkai Zheng, Liangqiong Qu, Ming Li* and Liqiang Nie. ACM MM. 2025. (*Corresponding Author)
[Paper][Project]
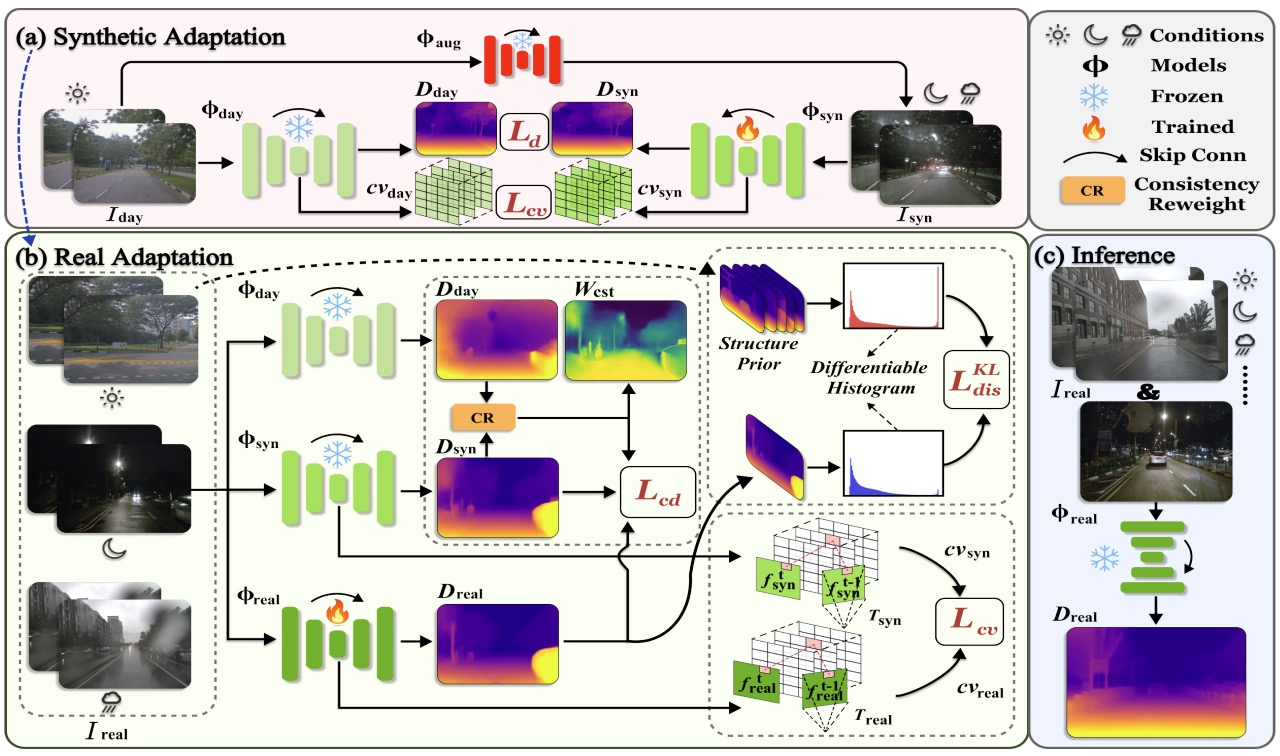 Synthetic-to-Real Self-supervised Robust Depth Estimation via Learning with Motion and Structure Priors
Synthetic-to-Real Self-supervised Robust Depth Estimation via Learning with Motion and Structure Priors
Weilong Yan, Ming Li, Haipeng Li, Shuwei Shao, Robby T. Tan. CVPR. 2025.
[Paper][Project]
 Uncertainty Quantification for Incomplete Multi-View Data Using Divergence Measures
Uncertainty Quantification for Incomplete Multi-View Data Using Divergence Measures
Zhipeng Xue†, Yan Zhang†, Ming Li†, Chun Li, Yue Liu, and Fei Richard Yu. IEEE TIP. 2025. (†Equal Contributors)
[Paper][Project]
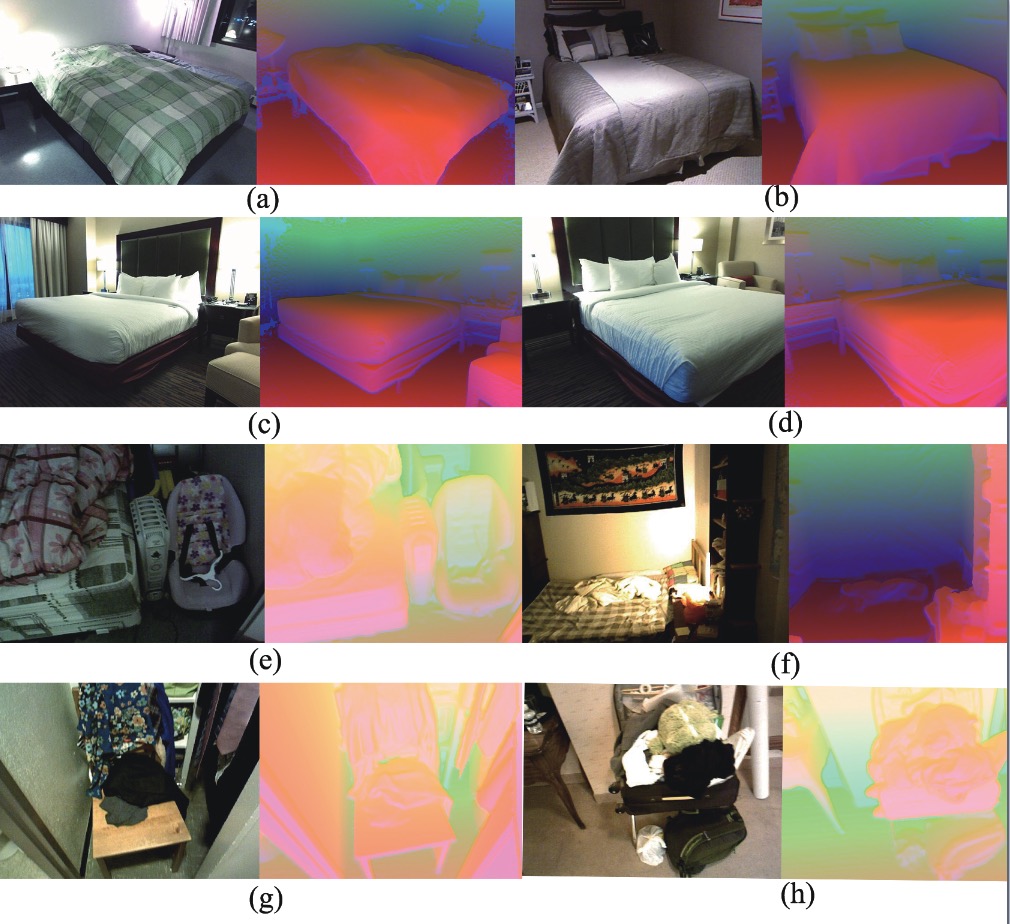 Uncertainty Quantification via Holder Divergence for Multi-View Representation Learning
Uncertainty Quantification via Holder Divergence for Multi-View Representation Learning
Yan Zhang†, Ming Li†, Chun Li, Zhaoxia Liu, Ye Zhang, and Fei Richard Yu. IEEE TMM. 2025. (†Equal Contributors)
[Paper][Project]
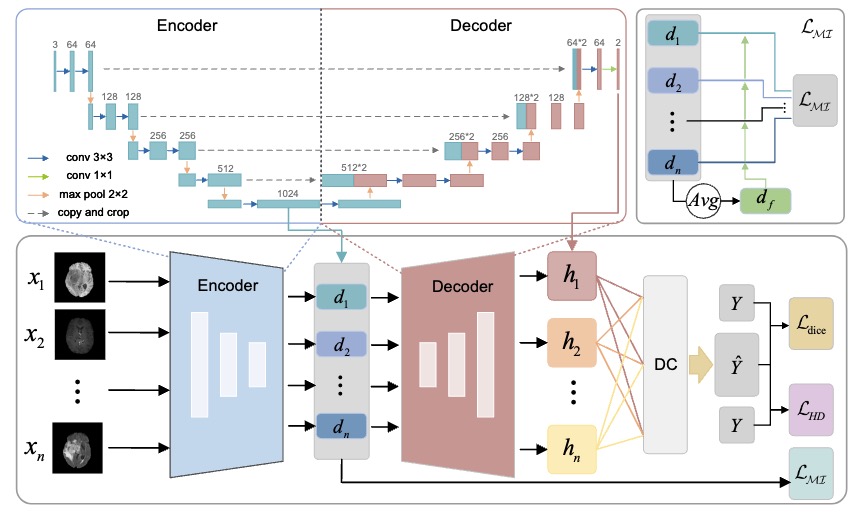 Robust Brain Tumor Segmentation with Incomplete MRI Modalities Using H¨older Divergence and Mutual Information-Enhanced Knowledge Transfer
Robust Brain Tumor Segmentation with Incomplete MRI Modalities Using H¨older Divergence and Mutual Information-Enhanced Knowledge Transfer
Runze Cheng†, Xihang Qiu†, Ming Li†, Ye Zhang, Fei Richard Yu, and Chun Li. IEEE/CAA Journal of Automatic Sinica. 2025. (†Equal Contributors)
[Paper][Project]
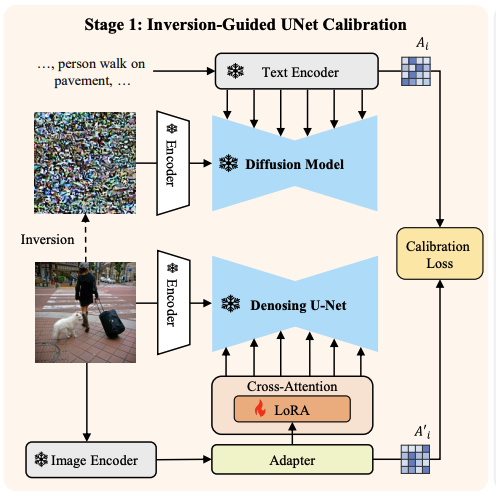 SPADE: Spatial-Aware Denoising Network for Open-vocabulary Panoptic Scene Graph Generation with Long- and Local-range Context Reasoning
SPADE: Spatial-Aware Denoising Network for Open-vocabulary Panoptic Scene Graph Generation with Long- and Local-range Context Reasoning
XIN Hu, Ke Qin, Guiduo Duan, Ming Li, Yuan-Fang Li, Tao He. ICCV. 2025.
[Paper][Project]
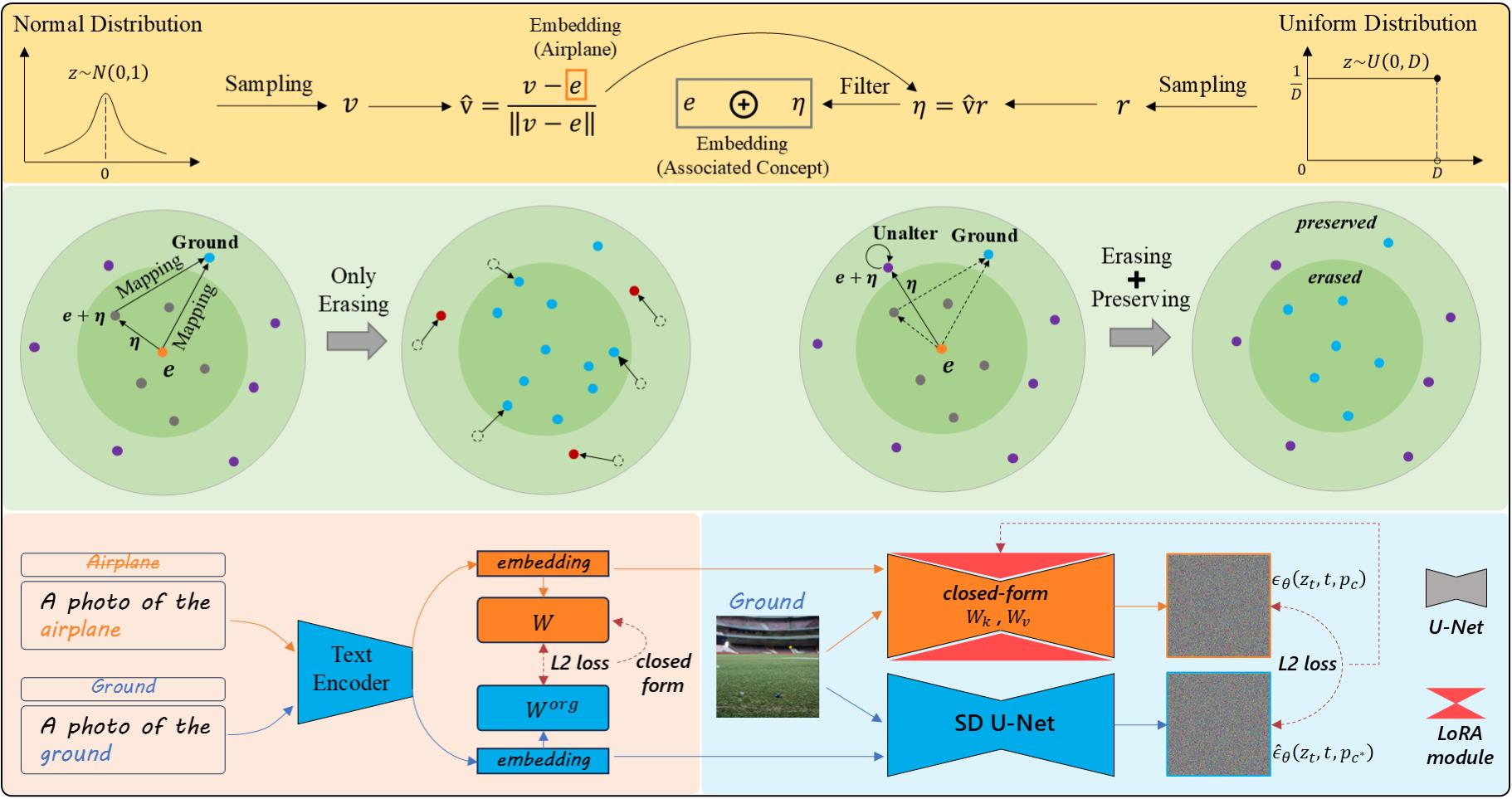 Corer: Concept Residue Erasing in Text-to-Image Diffusion Models
Corer: Concept Residue Erasing in Text-to-Image Diffusion Models
Yufan Liu, Jinyang An, Wanqian Zhang, Ming Li*, Dayan Wu, Jingzi Gu, Zheng Lin, and Weiping Wang. ICME. 2025. (*Corresponding Author)
[Paper][Project]
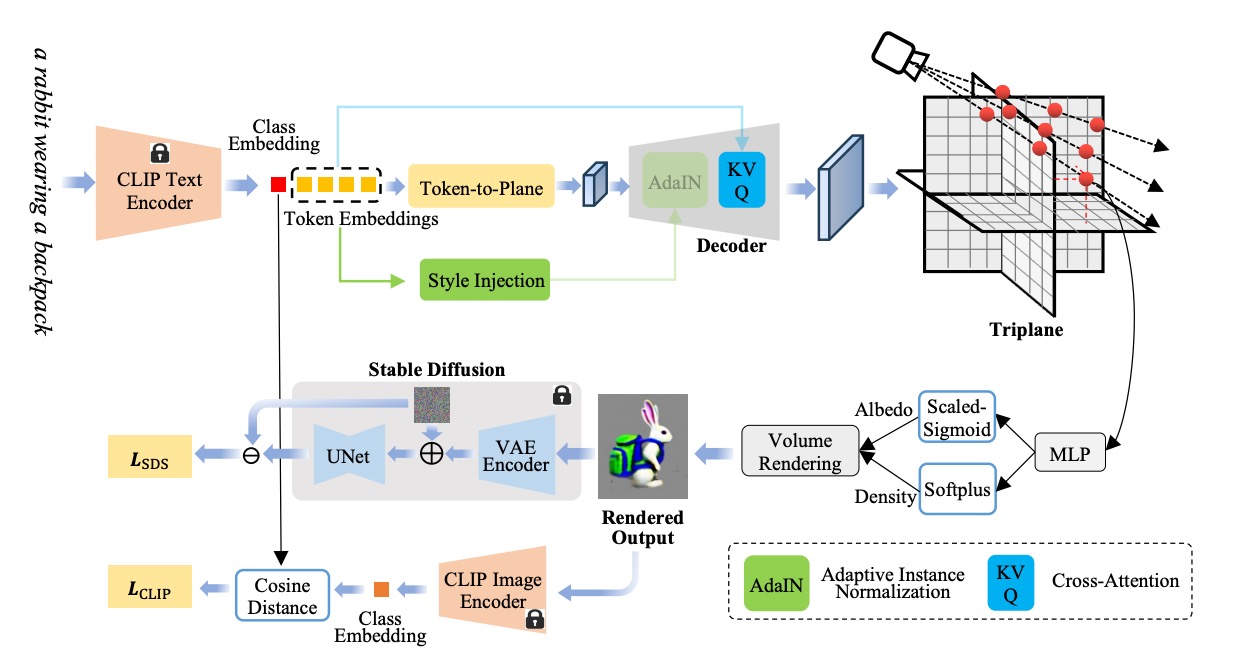 Instant3D: Instant Text-to-3D Generation
Instant3D: Instant Text-to-3D Generation
Ming Li, Pan Zhou, Jia-Wei Liu, Jussi Keppo, Min Lin, Shuicheng Yan and Xiangyu Xu. International Journal of Computer Vision. 2024.
[Paper][Project]
 DR-FER: Discriminative and Robust Representation Learning for Facial Expression Recognition
DR-FER: Discriminative and Robust Representation Learning for Facial Expression Recognition
Ming Li, Huazhu Fu, Shengfeng He, Hehe Fan, Jun Liu, Jussi Keppo and Mike Zheng Shou. IEEE TMM. 2023.
[Paper][Code]
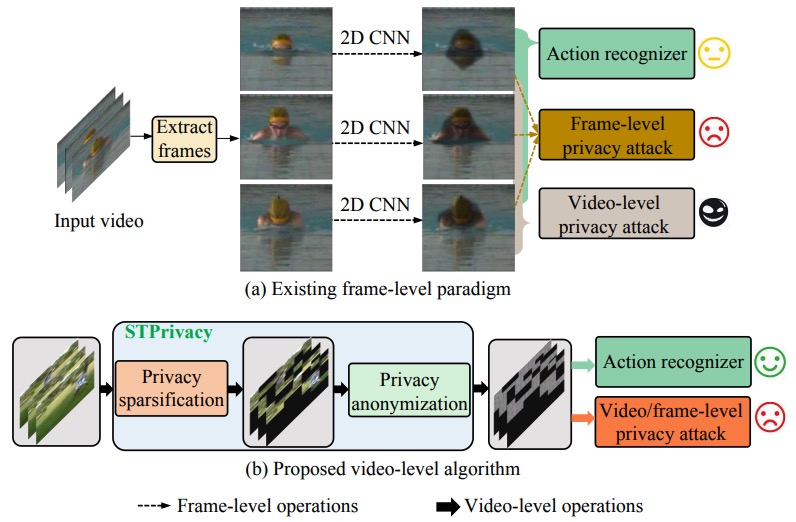 STPrivacy: Spatio-Temporal Privacy-Preserving Action Recognition
STPrivacy: Spatio-Temporal Privacy-Preserving Action Recognition
Ming Li, Xiangyu Xu, Hehe Fan, Pan Zhou, Jun Liu, Jia-Wei Liu, Jiahe Li, Jussi Keppo, Mike Zheng Shou, and Shuicheng Yan. ICCV. 2023.
[Paper][Code]
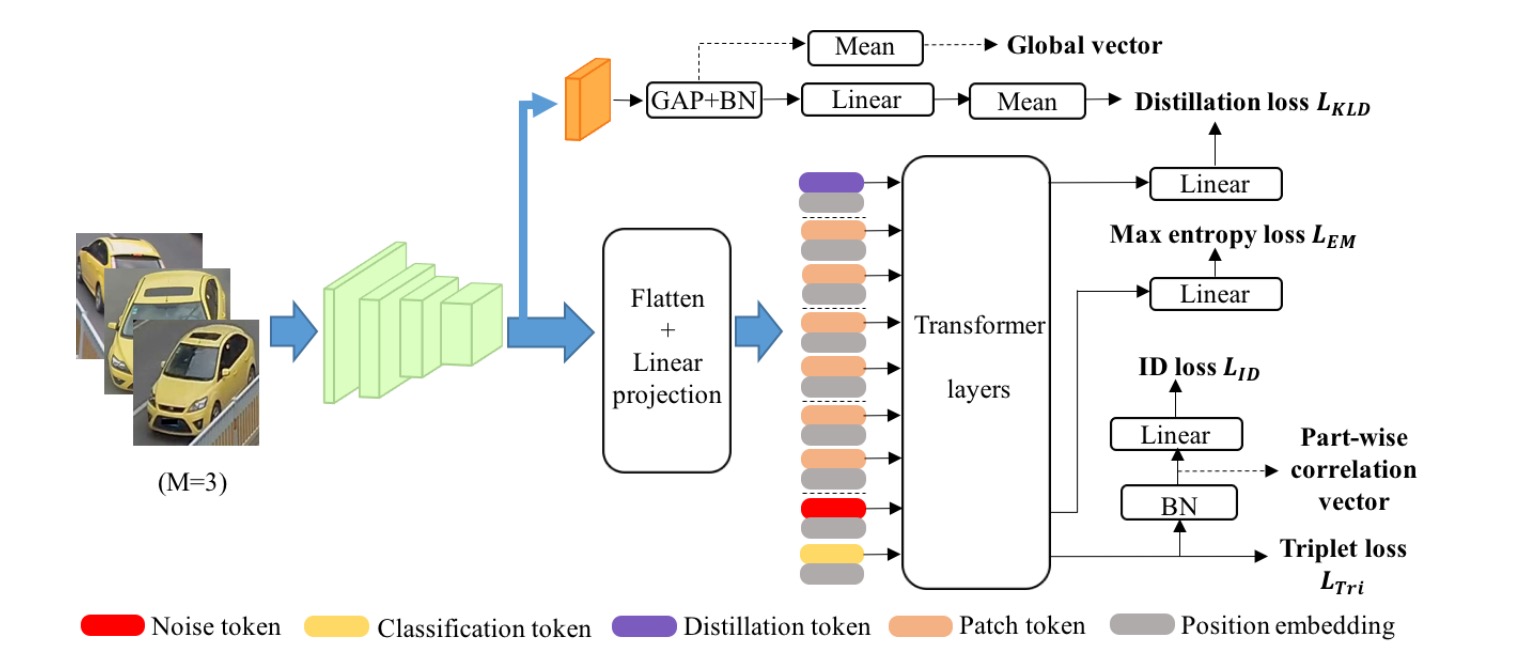 Exploiting Multi-view Part-wise Correlation via an Efficient Transformer for Vehicle Re-Identification
Exploiting Multi-view Part-wise Correlation via an Efficient Transformer for Vehicle Re-Identification
Ming Li, Jun Liu, Ce Zheng, Xinming Huang, and Ziming Zhang. IEEE TMM. 2021 (ESI Highly Cited Paper).
[Paper]
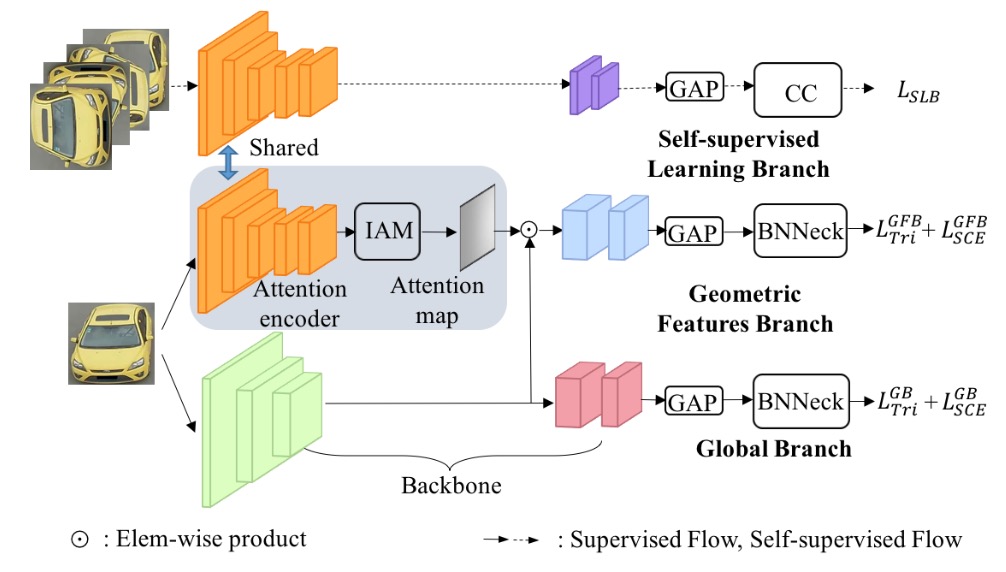 Self-supervised Geometric Features Discovery with Interpretable Attention for Vehicle Re-Identification and Beyond
Self-supervised Geometric Features Discovery with Interpretable Attention for Vehicle Re-Identification and Beyond
Ming Li, Xinming Huang, and Ziming Zhang. ICCV. 2021.
[Paper][Code]
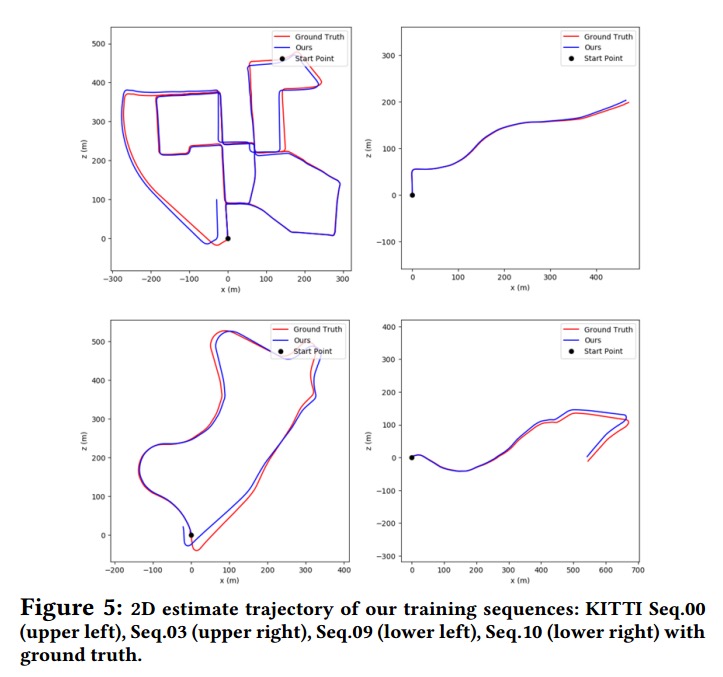 LodoNet: A Deep Neural Network with 2D Keypoint Matching for 3D LiDAR Odometry Estimation
LodoNet: A Deep Neural Network with 2D Keypoint Matching for 3D LiDAR Odometry Estimation
Ce Zheng, Yecheng Lyu, Ming Li, Ziming Zhang. ACM MM. 2020.
[Paper]
